提升服務效能、減輕DB負擔!(2): Materialized View
View 介紹、Materialized View介紹、比較Low Level Caching差異、在 Rails 中使用 view
這是我整理 cache 相關的第二篇。上一篇主要是站在 Rails 的角度,分享基本的 memcached、redis 等支援方式的介紹,最後也有本地跟 Heroku 的實作。
看過上一篇,相信各位大致上都已經知道怎麼暫時 Hold 住資料,不要毫無限制的 Query 了。
這陣子工作蠻忙,也用了些時間學習一個新玩意兒— Materialized View,發現它也可以用來做快取功能。若還不清楚 View 是什麼,可以先稍微看一下再進入 Materialized View。
Note: 這邊使用的資料庫也是 PostgresQL。
目錄
- View是什麼?
- View對效能有什麼幫助嗎?
- Materialized View 是什麼?
- 利用 MView 暫存的特性,來優化效能
- MView 應用情境範例
- 與 Low Level Caching 比較圖
- 在 Rails 安裝 scenic 來整合 view
View是什麼?
View(檢視表)是關連式資料庫中的一種特殊資料表。它是由一個查詢指令所做成,並存放在資料庫來「代表這個指令」的物件。每次使用他都會觸發這個指令來做查詢。
簡單來說,你把一串SQL查詢指令做成一個叫 myshortcut 的View,下次要做同樣查詢時只要使用 select * from myshortcut 就可以做同樣的查詢。你也可以再加上條件,他就會把這些條件加到背後那串指令。
假設你的老闆說:「我每天想大概看一下,近一日內新用戶來自哪裡?分別有多少個?」。這時候你發揮你的專長,寫了下面這個查詢,也得到老闆要的結果。

接著,時間一天一天過去。每天都要上資料庫重寫一次這個指令,來撈資料給老闆看,心裡覺得很藍瘦。
為了更方便查詢,此時你就可以將它做成 View。我們用 create view 檢視表名稱 as 想要的指令 來建立檢視表。

這個指令執行後,這串 select 的指令就會被存進資料庫,成為叫做 new_users_count_by_country 的 View。下次你要做相同查詢時,只要寫 select * from new_users_count_by_country 就會拿到一模一樣的結果囉!

可想而知,在 Query 長一點的時候做成 View,就會方便很多。
View對效能有什麼幫助嗎?
很好,回來我們的主題。View 雖然方便,它會有什麼效能上的改善嗎?
剛剛的範例,雖然在資料庫內看起來好像是一個 table,但是每次使用它查詢其實都會重跑一次裡面的指令。
我們使用 explain analyze 可以看到,它其實只是直接執行剛才你 View 裡面寫的指令:

所以,一般的View 並不會有任何效能提升。
當你的 Query 內部很多需要大量運算的語法(JOIN、SUM等),一樣會造成資料庫的負荷。
現在你知道 View 只是一個省力的查詢捷徑,沒什麼特別的優化。而今天要跟各位介紹另一種東西,叫做 Materialized View。它具有一些特別的性質,可以讓我們來做效能優化的應用。
Materialized View是什麼?
又稱「實體化檢視表」(以下簡稱 MView)。它跟 View 一樣是將一個查詢存起來,但建立同時會先執行一次你寫的指令,並且把結果用資料表的形式存起來。你沒聽錯!他具有儲存結果的功能!
我們把剛才的指令建成一個 MView。跟建 View 差不多,就是多了materialized 這個關鍵字。
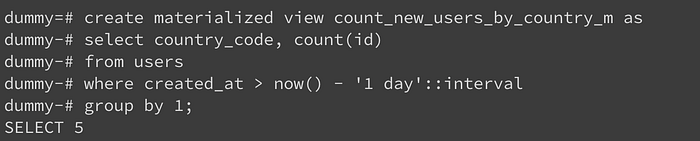
這個指令執行後,這串指令會被存進資料庫,成為名叫 count_new_users_by_country_m 的實體化檢視表。同時會自動執行一次裡面的查詢,並把結果儲存到其中。
細心一點的話,你會發現我們前面建立 View 時只回傳了 “CREATE VIEW”,而此時卻回傳 “SELECT 5”,可發現他這時候執行了你的指令,把 5列結果儲存了起來。
那我們對實體化資料表做搜尋,會不會觸發背後的查詢?我們一樣透過 explain analyze 來查看細節:

如你所見,這時它只是單純的 select * from 我們的m_view 而已。實際上是直接從先前的儲存結果中查詢,就好像你直接 select 某一個資料表一樣。
此外,因為 MView 他就是一個真的有存資料的表,你甚至可以加 Index 來加速搜尋。你是不是也感受到這個表的「實體化」了呢?。

透過refresh來刷新資料
雖然他有儲存功能,但畢竟他還是View的一種,並不能直接去改動他的資料。它在建立時會執行一次裡面的指令來儲存結果,之後我們必須透過使用「refresh materialized view」來刷新資料。這樣就會使它再執行一次背後的查詢指令,並用新的結果蓋掉之前舊的。
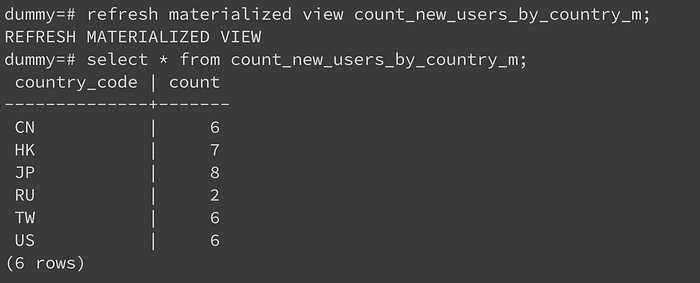
此外,如果這個表很常被查詢,你可能會擔心查詢當下,剛好這個表正在被整個 refresh 更新,資料被鎖住的狀況。
這時候你可以用 concurrently 的方式來 refresh,這樣 PostgresQL 就不會直接把整張表鎖住,而是會另外產生一份新的表來做比對,針對有更動的列來更新。但使用 concurrently 有一個前提 — 表內要有一或多個 unique index。

利用MView暫存的特性,來優化效能
假設今天我想看「前一天有多少香港的新用戶」,當時間到了今天,這個資料一天內就完全不會改變,我們只要每天算一次就好,沒有必要每次都去算。
也就是說,我們可以透過這種「暫存報表」的方式,來當作快取使用,進而改善服務的效能。
如果我們的服務,需要用到像這樣運算量大的查詢,就可以把它寫成一個 Materialized View,讓我們自己決定多久 refresh 一次,而非讓服務把我們的資料庫算到爆。像上面的例子一天 refresh 一次就好。
MView 應用情境範例
再給各位一個範例。假設今天有一個像是 Netflix 的網站,且我們會儲存每次用戶觀看影片的紀錄:名叫 video_watching_records 的資料表,大概長這樣:
同時需要一隻API,來讓用戶知道他「看了哪些影集、分別看了多久」。
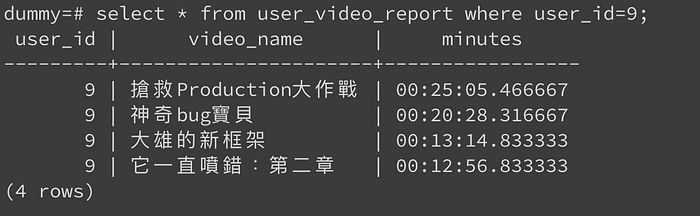
假設這個用戶的 user_id=9 好了。為了得到這些資訊,我們的查詢跟結果如以下:
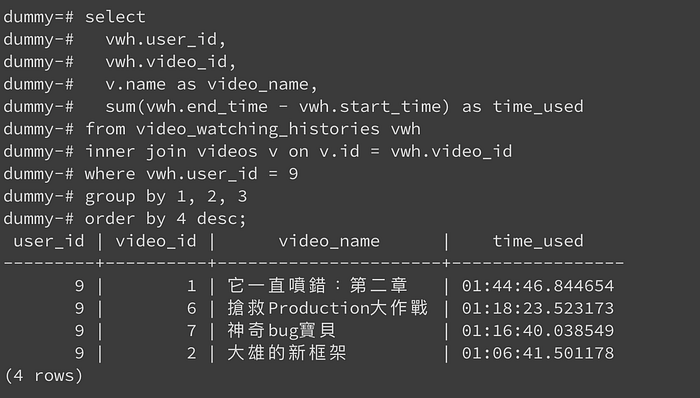
其中我們因為要統計看多久,就有用到 sum 這個聚合方式。但當 video_watching_records 這個表很大的時候,我們不希望每個人一打這隻api,都會重算一次。
這時候你可以像我上一篇提到,在「伺服器」內做 Low Level Caching。每個用戶存取API時,會從資料庫針對他算好一次存入快取,並且設定過期時間。只是這樣每個人第一次打的時候都會算一次,若太多人同時重算,也是很可怕的(汗。
今天這個範例,我建議用 MView 這個方法來做,把「暫存」的概念放在一個統一的表上。
做法是:把整個 video_watching_histories 做成一個叫做 user_video_report 的 MView。

注意製作時我們不去寫 where user_id=9 這個條件,而是把整個觀看紀錄表跑一次。雖然運算量大,但我們可以控制何時才會 refresh 它。
之後想針對某個用戶查詢,就再從這個 user_time_report 去用 user_id=9 來刮出他的紀錄。
這個透過我們指令整理好的報表,相對資料筆數較少,也可以做 index,對他搜尋非常快速。
再來我們就可以自行決定,要每隔多久來 refresh 一次。你可以使用 cronjob 或是使用ORM 搭配 scheduler。
像我自己是寫 Rails 的,剛好就可以用 sidekiq-scheduler 這個套件。如你是用 Node.js 的話,可以參考 Bree 這個套件~
與Low Level Caching比較

看圖可以發現說這兩種快取方式很不一樣。
Low Level Caching
是快取個別 API 查詢的結果。我們可以針對個別 API 分別設定快取時間。如果同樣結果還在快取就跳過搜尋,直接回傳結果,進而提升 API 速度。
這種我建議是用在「對大家來說結果都一樣的API」,例如:熱門文章列表、排行榜等。
Materialized View
是在資料庫中「先苦後甘」,先辛苦算完一次後快取一整個表。服務的 API 就可改用比較簡短的SQL指令來搜尋,尤其再加上index後,速度會提升非常多。之後我們再決定何時 refresh 來辛苦一次,中間這段空檔,就像快取過期時間。
這個我則是建議用在「想要個別看長期累積紀錄」報表,像是這種每個用戶電影看多久、個別用戶每月總支出,依此類推。
整理來說,效能優化、減輕負擔在哪?
效能優化是在可以更快回傳結果(藍色);減輕資料庫負擔則是因為調整成「不是每次要資料,都執行一次大量查詢」(紅色)。
在Rails 安裝scenic來整合 view
接下來要跟各位介紹在 Rails 中怎麼使用,我們可以透過 scenic 這個 gem ,來把 View 相關的功能擴充到 ActiveRecord上。它讓我們可以使用 Migration 來新增、刪除、管理 view版本。
STEP1: 安裝 scenic
gem 'scenic'記得要 bundle install
STEP2: 準備我們要做的 view 檔案們
scenic 提供我們一個新的generator,可以用來產生 view 的相關檔案。
我這邊的範例是產生 MView,如果你只要產一般的 view ,就不用 --materialized 這個選項。
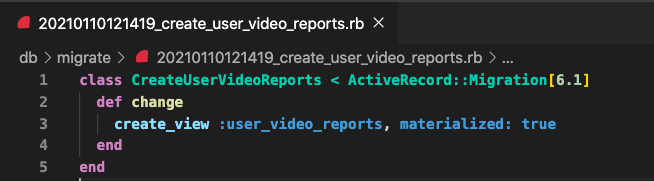
bundle exec rails generate scenic:view user_video_report --materialized執行後會產生
- db/views 資料夾
- 用來產生sql用的檔案(是空的)
- 以及 ActiveRecord 的 Migration 檔案

STEP3: 撰寫我們要儲存的查詢指令
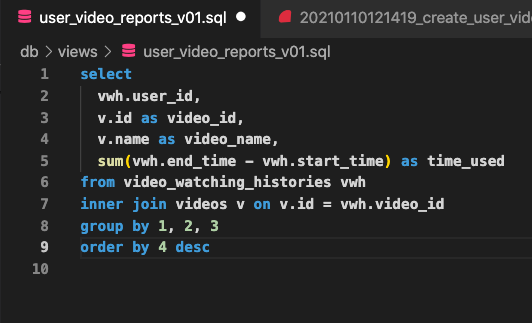
找剛剛它幫我們產的 .sql 檔案,應該是空白的。這邊只要寫我們要的查詢就好,不需要寫 create materialized view,因為我們的 migration 檔案已經註明了。
你應該有注意到檔名有個 v01 ,也就是第一版本。下次你要更新這個查詢內容時,可直接重打 STEP2 的指令,它就會幫你產生 v02 的sql檔案,還有新的 Migration 檔案。是不是很方便呢?
STEP4: 跑migrate

STEP5: 為這個 View 建立一個 model
scenic 擴充了 ActiveRecord 的 Model,讓它可以支援各種 View 的存取。這邊我們就手動去建一個 app/models/user_video_report.rb ,也讓他繼承 ApplicationRecord 。
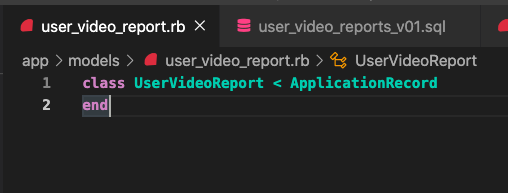
此外,因為我們一般都不會從 View/ Materialized View 去寫入資料,為了保險起見我們可以宣告這個model 是 readonly。
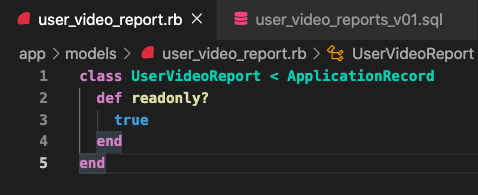
STEP6: 在 Model 宣告 refresh 的方法
接下來我們可以在同個檔案宣告 refresh 方法,這樣就可以從 Rails 來刷新資料了。這邊可以帶各種 option,例如是否要 concurrently 等。
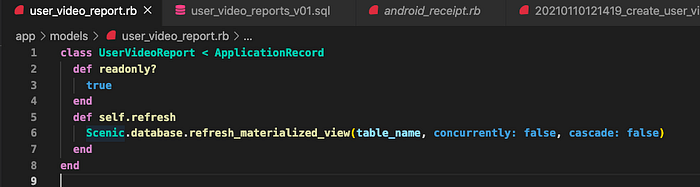
STEP7: 開始使用
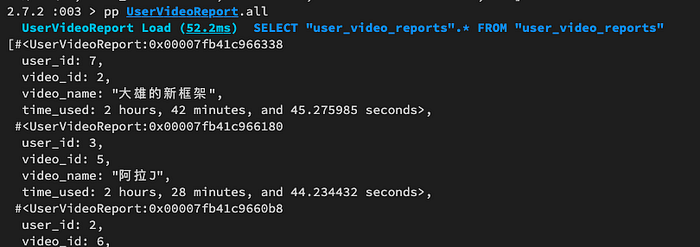
接下來就可以在 Rails 各處使用,要怎麼用就看你的造化了!也可以先開 rails console 來玩。

STEP 8: 找一個喜歡的方式來 Refresh
再來我們要想辦法定期去 refresh 它。畢竟都用 Rails 了,還是推薦用 sidekiq 搭配 sidekiq-scheduler 比較方便。
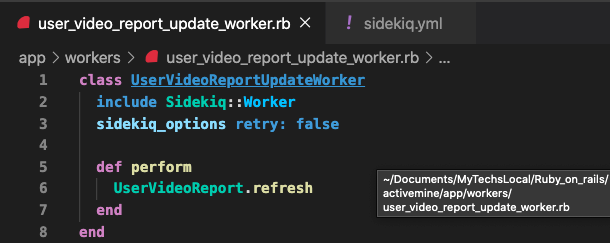
假設我每天早上6點(+08:00)要跑一次,範例如下
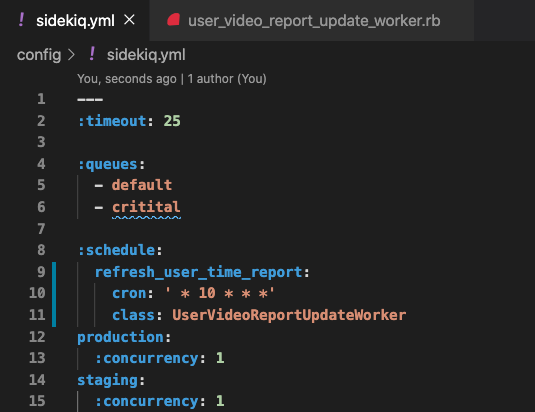
補充
更新 View
再走一次 STEP2,他就會產生 update_view 的 migration 以及v02 的sql檔案,再跑一次 migrate 就好。
刪除View
刪除則是自己建一個 Migration,裡面寫 drop_view user_time_report ,再跑 migrate 就完成了。其他詳細資訊可以在這裡找到,都有清楚範例。
以上分享,感謝你耐心讀到這裡。若有其他使用心得或建議,歡迎交流指正!
References
and 工作上使用經驗
